ほぼまっさらの状態からJenkinsを入れたので手順メモ。
内容はシステムアップデートとJava&Jenkinsのインストールです。
ほぼまっさらの状態からJenkinsを入れたので手順メモ。
内容はシステムアップデートとJava&Jenkinsのインストールです。
AWSのサーバはクラウドサーバのEC2とVPSサーバのLightsailがあります。
大雑把に言うと自由自在で従量課金のEC2と安定して安い月額のLightsailです。
コストダウンのためにWordPressブログの移行をしたのでそのメモ。
定期的に更新される情報。
数字だけで小難しかったり、単体で見てもわかりにくかったり。
そういうのをDBにスタックしてわかりやすく表示する機能を作ってみたい。
次の要素があると作りやすい。
今回は練習作としてFXのスワップ金利を対象に作ってみた。
※スワップ金利とは2国間の金利差を日割りにして付与するものです。
基本的にAWSで収まる設計にする。
概要 : CloudWatch -> Lambda -> DynamoDB <- Lambda <- API <- S3
次に持ってきたJSONをグラフ化する。
グラフ作成系のJavascriptは結構あるけど、どれも面倒な感じ。
今回は比較的簡単そうでデザインと名前が好みのChart.jsを使ってみる。
これは基本機能は簡単ではあったけど、ちょっと変えようとすると難しい。
頻繁に仕様が変わっているのか、ブログや紹介記事なんかはまったく当てにならなかったので公式ドキュメント以外は信用しない方がいい(Update関連は公式通りではうまくいかなかったけど)。
出来上がったチャートはこんな感じ。アニメーションが心地良い。
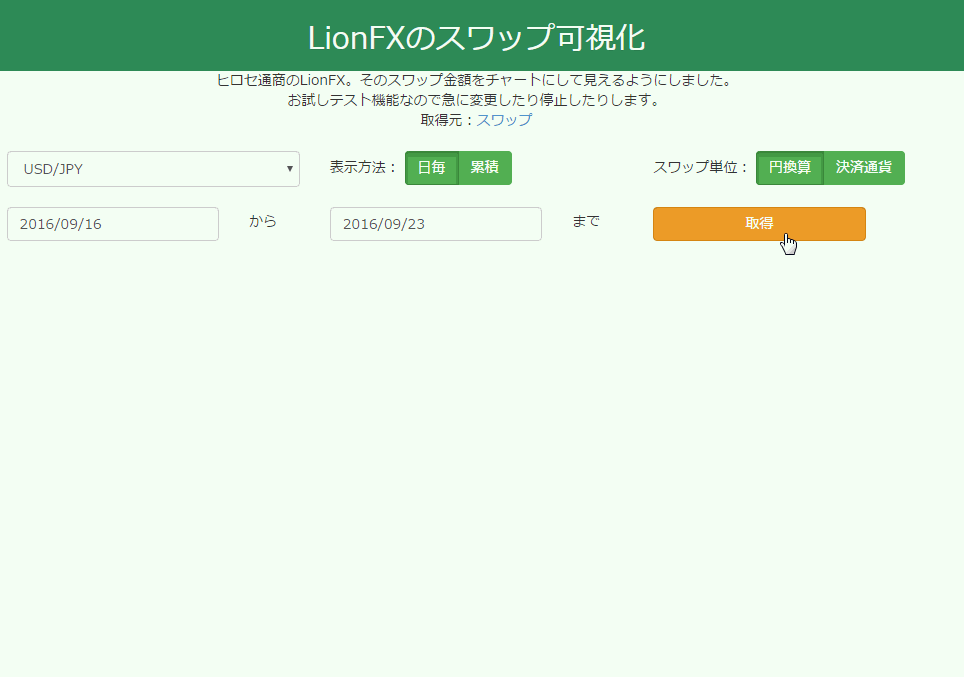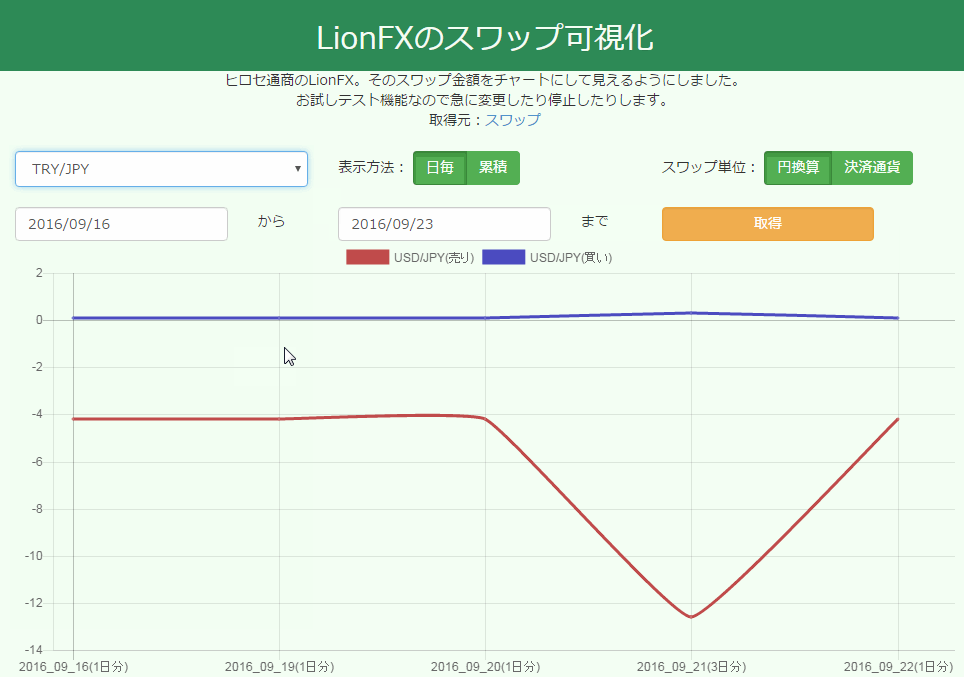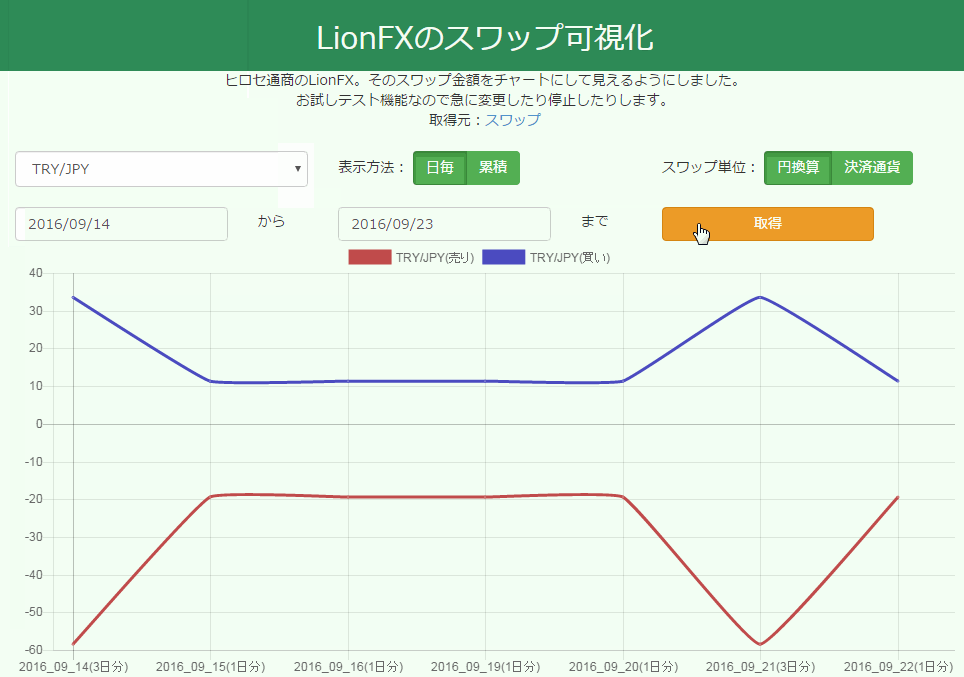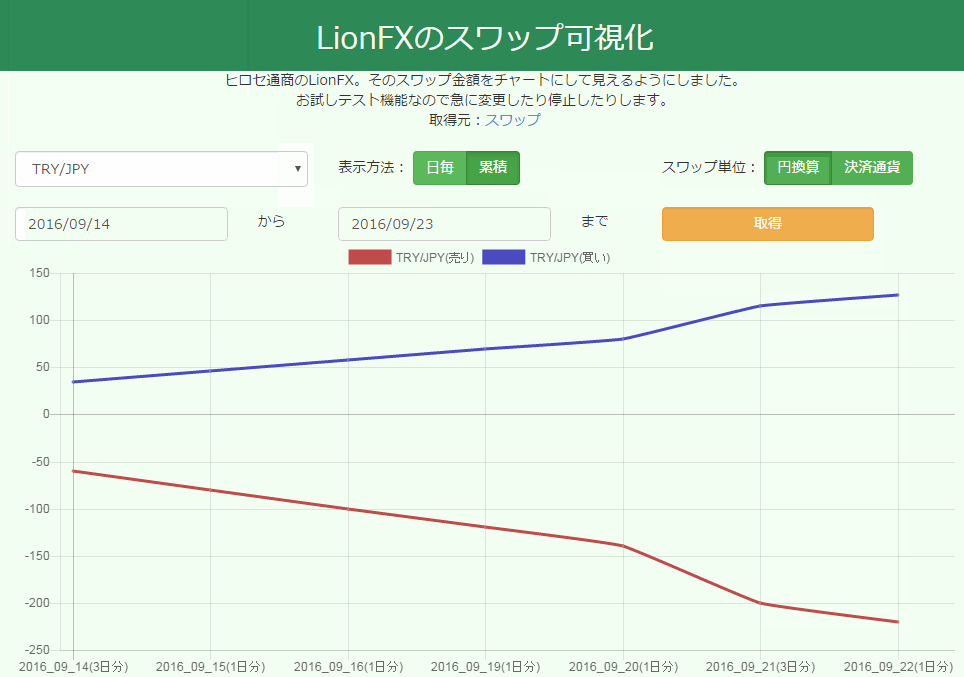
さて何をつくろうかな。
技術的にはクローリングとかスクレイピングとか呼ばれている。
クローリングはWebを自動で徘徊する技術で、スクレイピングはさらに欲しいものだけ抽出するような感じ。
例えばポータルのほうで技術ニュースリンクをまとめてるのはこの技術を使っている。
方法は色々あるけどAWSで簡単にできそうなものを2つ実装している。
けどいまいちしっくりこないので現状をまとめつつ、どう運用するのが一番いいか考えてみる。
1つ目の方法はEC2にヘッドレスブラウザを入れてJenkinsで管理するやり方。
2つ目の方法はLambdaで起動してCloudWatchで管理するやり方。
どっちもスクレイピング自体はjavascriptを中心にした方法で実現している。
■EC2+phantomjs+casperjs+Jenkins
EC2インスタンスを立ち上げてその中で好きなようにしようというスタンス。
phantomjsはヘッドレスブラウザでcasperjsはそのユーティリティ。
javascriptで実行できる画面描写のないブラウザを利用して情報を集める。
Jenkinsのジョブで収集スクリプトを起動したり、データを格納したりする。
インスタンス内でできることは何でもできるので拡張性が高い。
インスタンスのメンテナンスが必要。EC2インスタンスは起動時間課金なのですでに運用しているインスタンスに相乗りしたり、必要に応じて起動/停止をしないとお金がかかる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
var casper = require('casper').create(); casper.start('http://1つ目のサイト',function(){this.wait(20000);/*広告ページ待機*/}); casper.then(function(){ $(this.getHTML('DOM#dom',true)).each(function(){ my_json.a=$(this).prop('href'); }); }); casper.thenOpen('http://2つ目のサイト',function(){this.wait(20000);/*広告ページ待機*/}); casper.then(function(){ $(this.getHTML('DOM#dom',true)).each(function(){ my_json.b=$(this).prop('href'); }); }); casper.then(function(){ fs.write(FILE_NAME, JSON.stringify(my_json)); }); casper.run(); |
ヘッダをいい感じに設定すれば特に待つ必要はないかもしれない。
■Lambda+nodejs+cheerio-httpcli+CloudWatch
インスタンスを保持せずサービスとして使おうというスタンス。
cheerio-httpcliはnodejsのスクレイピング用モジュール。
LambdaにZIPを置いてevent sourceでCloudWatch Events – Scheduleを設定する。
メンテ不要でAWSの他サービスが使いやすい利点がある反面、Lambdaの制限がある。
特にマックス300秒の制約を気にしないといけないかも。
起動以外は取得、整形、格納なんかは全部Lambdaの中で行う。
実行時間のみ課金されるので使わないときのメンテが不要。
AWSの他サービスを使いやすい(IAM ロールの設定などが簡単)。
Lambdaの制約内でやる必要があるので拡張性は低め。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
var client = require('cheerio-httpcli'); client.fetch('http://1つ目のサイト').then(function (result) { result.$('DOM#dom').each(function(){ my_json.a=result.$(this).prop('href'); }); return client.fetch('http://2つ目のサイト'); }).then(function (result) { result.$('DOM#dom').each(function(){ my_json.b=result.$(this).prop('href'); }); }).catch(function (err) { console.log(err); }).finally(function () { fs.writeFile(FILE_NAME, JSON.stringify(my_json)); }); |
cheerio-httpcliに関しては作者さんがかなり丁寧に解説しているので使いやすかった。
どちらも多少ニッチな知識が必要だけどjavascriptを多少知っていれば難しいとこはないし、ググればすぐに情報が手に入るので実装は簡単だった。
クライアントアプリケーションを途中でかませたりするような場合にはEC2内でやって、AWS内だけで済む処理なら基本Lambdaにするのがいいかなと思う。
今回の組み合わせの他にもEC2でnodejs動かしたり、Lambdaでphamtomjs動かしたりする例も見かけたけど特にそうする理由はなさそう。
kimonoみたいな専用サービスを使うとスクレイピング実施部分はほぼノータイムでできるんだろうけど、利用するサービスが増えると色々と面倒見ないといけなくなりそうなのでしばらくはAWSに依存してみようと思う。
DynamoDBをAPIで使えるようにした。
次にAPIを通じてCRUD操作する方法を記録しておく。
基本的に公式ガイドを参照したけどわかりにくかったので他も色々見ながら試行錯誤した。
検索するといろんな情報(古い書き方、非推奨の書き方や別の言語での書き方)が入り混じっていて結構わかりにくかった。
payload.TableNameで指定したテーブルにpayload.Item内のJSONを新規登録する。
テーブル作成時にプライマリーキーに設定した属性は必須。
それ以外はJSONであれば自由。
また、プライマリーキーの値がすでにあるものであった場合はレコードそのものを上書きする。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "operation":"create", "payload":{ "TableName":"test", "Item":{ "id":"test", "name":"testName", "type":{ "id":"create", "function":"createFunction" } } } } |
payload.TableNameで指定したテーブルにpayload.Keyにプライマリーキーを指定して1レコードを取得する。
|
1 2 3 4 5 6 7 8 9 |
{ "operation":"read", "payload":{ "TableName":"test", "Key":{ "id":"test" } } } |
|
1 2 3 4 5 6 7 8 9 10 |
{ "Item": { "name": "testName", "id": "test", "type": { "id": "create", "function": "createFunction" } } } |
createで同一プライマリキーを指定したときとは違って、レコードの一部を変更できる。
payload.Keyで指定したレコードの更新を行う。
プライマリキー属性は更新できないので、その場合はdeleteしてcreateしなおす必要がある。
また、AttributeUpdatesで処理を定義することもできるが現在は非推奨とされている。
まずUpdateExpressionに式を記入する。
以下の4つの式が使えるがSET, REMOVEの他は基本使わない。
次にExpressionAttributeNamesに属性名を定義。直接UpdateExpressionで指定してもいいが予約語とかぶらないように注意する。
同様にExpressionAttributeValuesに代入する値を定義。
ReturnValuesは以下から選ぶ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "operation":"update", "payload":{ "TableName":"test", "Key":{ "id":"test" }, "UpdateExpression": "SET #tree1.#tree2 = :a", "ExpressionAttributeNames": { "#tree1": "type4", "#tree2": "a1" }, "ExpressionAttributeValues":{ ":a":"updated" }, "ReturnValues":"UPDATED_NEW" } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "operation":"update", "payload":{ "TableName":"test", "Key":{ "id":"test" }, "UpdateExpression": "REMOVE #type", "ExpressionAttributeNames": { "#type": "type2" }, "ReturnValues":"UPDATED_NEW" } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
{ "operation":"update", "payload":{ "TableName":"test", "Key":{ "id":"test" }, "UpdateExpression": "ADD #tree :a", "ExpressionAttributeNames": { "#tree": "num" }, "ExpressionAttributeValues":{ ":a":5 }, "ReturnValues":"UPDATED_NEW" } } |
DELETEは今回の例だと使えないため割愛。
書き方 : DELETE HashSet [“a”,”b”,…]
プライマリキーを指定してレコードを削除する。
|
1 2 3 4 5 6 7 8 9 |
{ "operation":"delete", "payload":{ "TableName":"test", "Key":{ "id":"test" } } } |
テーブルを指定してレコード一覧を取得する。
|
1 2 3 4 5 6 |
{ "operation":"list", "payload":{ "TableName":"test" } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "Items": [ { "name": "firstName", "id": "firstRecoed" }, { "name": "secondName", "id": "secondRecoed" } ], "Count": 2, "ScannedCount": 2 } |
外からAPIを叩いてデータをDBに保存してみたかったので試してみた。
プラットフォームはAWSオンリー。
以下のサービスを使って連携をしてみる。
まずAWSでNoSQL DBサービスのDynamoDBの準備をする。
AWSのサービスはそれぞれテスト機能があるので一番深いところから用意していくとトントン進む気がする。
以上でDBの準備完了。簡単!
LambdaはAWSで用意されているコードの実行サービス。
Java,Nodejs,Pythonコードを実行可能(今回はNodejs)。
なのでここには処理の実行部分を書く。
今後処理の内容を弄るときには基本的にここをでロジックを書く必要がある。
今回やりたいことはBlueprint(色々セットで作ってくれるテンプレートのようなもの)で用意されているのでそれを使う。
これで準備完了なのでテストしてみる。
Lambdaの左上のTestボタンを押すとeventの中身を直接入力してテストできる。
以下のJSONを入力してテストすると実際にレコードが登録される。
|
1 2 3 4 5 6 7 8 9 10 |
{ "operation":"create", "payload":{ "TableName":"test", "Item":{ "id":"firstRecoed", "name":"firstName" } } } |
DynamoDBのtestテーブルを見るとレコードが追加されているのが確認できる。
ブラウザの拡張でREST APIテスト用のアドオンがあるのでそれで実際の動作を確かめる。
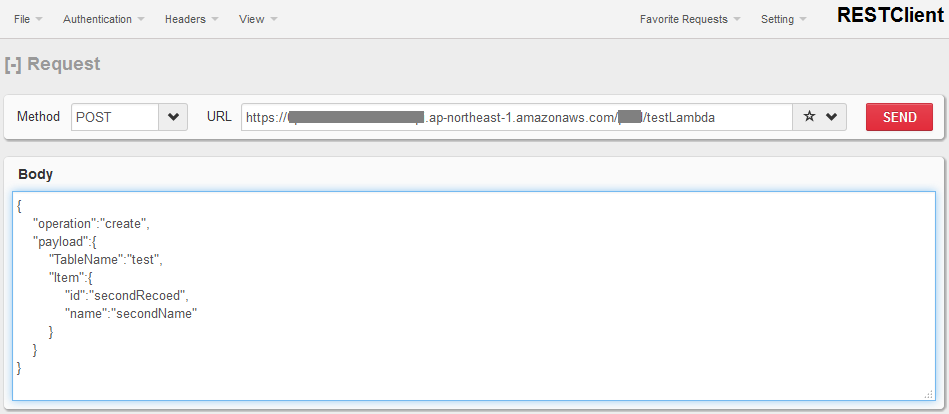
URL:APIエンドポイント
Method:POST
Body:
|
1 2 3 4 5 6 7 8 9 10 |
{ "operation":"create", "payload":{ "TableName":"test", "Item":{ "id":"secondRecoed", "name":"secondName" } } } |
Dynamoのtestテーブルを見ると2つのテストで入れたレコードが確認できる。
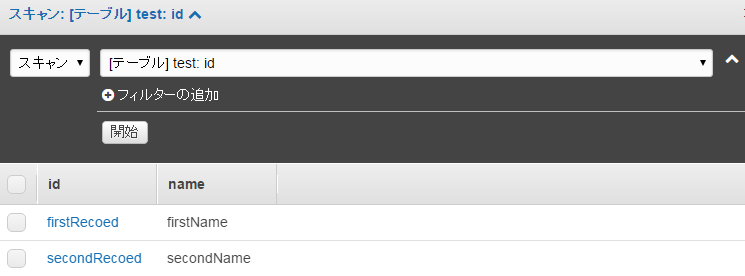
このままだとURLをたたけば誰でもデータベース操作できてしまうのでLambdaの処理を絞ったり、APIに認証を設定したりする必要がある。